

K-Means Clustering: Pengertian, Cara Kerja, Kelebihan, dan Kekurangannya
K-means clustering merupakan salah satu algoritma machine learning yang sederhana dan populer digunakan untuk memecahkan masalah pengelompokan data. Dalam machine learning, k-means clustering termasuk ke dalam jenis algoritma unsupervised learning.
Pengertian K-means Clustering
K-Means clustering adalah algoritma unsupervised learning yang dipakai untuk mengelompokkan dataset yang belum dilabel ke dalam kluster yang berbeda. Simbol K pada K-means clustering menandakan jumlah kluster yang digunakan.

Kluster mengacu pada kumpulan titik data yang dikumpulkan bersama karena kesamaan tertentu. Jika K = 2, maka akan ada 2 kluster, dan jika K = 3 maka terdapat 3 kluster, begitu seterusnya.
Dengan demikian K-means clustering dapat didefinisikan sebagai algoritma iteratif yang membagi kumpulan data (dataset) yang tidak berlabel menjadi k kluster yang berbeda sedemikian rupa sehingga setiap kumpulan data hanya dimiliki oleh satu kelompok yang memiliki properti serupa.
Cara Kerja Algoritma K-Means
Algoritma ini didesain untuk memungkinkan kita mengelompokkan data ke dalam grup yang berbeda dengan cara yang lebih mudah berdasarkan variabel tertentu tanpa perlu melakukan proses training.
Hal ini karena k-means clustering merupakan algoritma unspervised learning berbasis centroid, dimana setiap cluster diasosiasikan dengan centroid. Tujuan utama dari algoritma ini adalah untuk meminimalkan jumlah jarak antara titik data dan cluster yang sesuai.
Algoritma K-means mengambil dataset yang tidak berlabel sebagai input, kemudian membagi dataset menjadi sejumlah k cluster, dan mengulangi proses tersebut sampai tidak menemukan cluster terbaik. Nilai k harus ditentukan sebelumnya dalam algoritma ini.
Algoritma k-means clustering melakukan dua tugas utama, yakni:
- Menentukan nilai terbaik untuk titik pusat K atau centroid dengan proses iteratif (perulangan).
- Menetapkan setiap titik data ke pusat k terdekat. Titik-titik data yang dekat dengan pusat-k tertentu, kemudian dibuatkan sebuah kluster
Oleh karena itu setiap cluster memiliki titik data dengan beberapa kesamaan, dan cukup jauh dari cluster lainnya.
Diagram di bawah ini adalah ilustrasi cara kerja Algoritma Clustering K-means
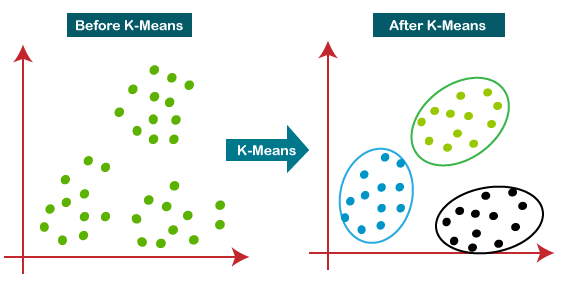 |
| Sumber: javatpoint.com |
Cara kerja algoritma K-Means dijelaskan dalam langkah-langkah di bawah ini:
Langkah-1: Pilih angka K untuk menentukan jumlah cluster.
Langkah-2: Pilih titik K atau centroid secara acak.
Langkah-3: Tetapkan setiap titik data ke centroid terdekat, yang akan membentuk cluster K yang telah ditentukan.
Langkah-4: Hitung varians dan tempatkan centroid baru dari setiap cluster.
Langkah-5: Ulangi langkah ketiga, yang berarti menetapkan kembali setiap titik data ke centroid terdekat baru dari setiap cluster.
Langkah-6: Jika ada penugasan ulang, lanjutkan ke langkah-4 jika tidak, lanjutkan ke FINISH.
Langkah-7: Model sudah siap.
Kelebihan dan Kekurangan K-Means
Kelebihan Algoritma K-means
Adapun kelebihan dari algoritma K-Means adalah sebagai berikut:
- Relatif sederhana dan mudah untuk diterapkan.
- Dapat diskalakan untuk dataset dalam jumlah besar.
- Mudah beradaptasi dengan contoh baru.
- Umum diimplementasikan ke cluster dengan bentuk dan ukuran yang berbeda, seperti cluster elips.
Kekurangan Algoritma K-means
Adapun kelemahan atau kekurangan dari algoritma K-means di antaranya:
- Perlu menentukan nilai k secara manual
- Sangat bergantung pada inisialisasi awal. Jika nilai random untuk inisialisasi kurang baik, maka pengelompokkan yang dihasilkan pun menjadi kurang optimal.
- Dapat terjadi curse of dimensionality. Masalah ini timbul jika dataset memiliki dimensi yang sangat tinggi. Cara kerja algoritma ini adalah mencari jarak terdekat antara k buah titik dengan titik lainnya. Mencari jarak antar titik pada 2 dimensi, kemungkinan masih mudah dilakukan. Namun apabila dimensi bertambah menjadi 20 tentunya hal ini akan menjadi sulit.
- K-means mengalami kesulitan mengelompokkan data di mana cluster memiliki ukuran dan kepadatan yang bervariasi.
Contoh Penerapan K-means Clustering
Clustering adalah teknik yang banyak digunakan dalam industri. Teknik ini sebenarnya digunakan di hampir setiap bidang, mulai dari perbankan hingga mesin rekomendasi, pengelompokan dokumen hingga segmentasi gambar.
Berikut adalah beberapa penerapan dari K-means clustering
- Segmentasi pasar
- Pengelompokan dokumen
- Segmentasi gambar
- Kompresi gambar
- Kuantisasi vektor
- Analisis klaster
- Identifikasi daerah rawan kejahatan
- Deteksi penipuan asuransi
- Analisis data angkutan umum
- Pengelompokan aset IT
- Segmentasi pelanggan
- Mengidentifikasi data kanker
Penutup
Demikianlah penjelasan lengkap mengenai algoritma K-Means Clustering. Semoga bermanfaat.
Apabila tertarik mengenai artikel seputar algoritma machine learning seperti ini, Anda bisa mengunjungi rubrik Machine Learning atau membaca artikel lainnya mengenai algoritma K-Nearest Neighbor yang juga menarik untuk dibaca.
Salam!

Posting Komentar untuk "K-Means Clustering: Pengertian, Cara Kerja, Kelebihan, dan Kekurangannya"
Komentar SPAM akan disensor. Harap gunakan kalimat yang tidak menjurus pada SARA dan pornografi.