
Apa itu Algoritma Breadth First Search? Pengertian dan Cara Kerjanya
Graph traversal adalah metodologi yang umum digunakan untuk menentukan posisi titik dalam graph. Sebelumnya, graph adalah kumpulan dati titik (node) dan garis dimana pasangan-pasangan titik (node) tersebut dihubungkan oleh segmen garis. Node ini biasa disebut simpul (vertex) dan segmen garis disebut sisi/ruas (edge).

Graph traversal berarti mengunjungi setiap simpul (vertex) dan tepi (edge) tepat satu kali dalam urutan yang jelas atau sistematis dari sebuah grafik.
Saat menggunakan algoritma graph traversal tertentu, pastikan terlebih dahulu setiap simpul dari graph dikunjungi tepat satu kali. Urutan di mana simpul dikunjungi sangat penting dan bergantung pada algoritma yang ingin dipecahkan.
Sebelum kita melangkah, terlebih dahulu perlu kita kenali dua istilah penting terkait dengan graph traversal:
 |
| Sumber: edureka.co |
- Mengunjungi sebuah node (visiting a node): seperti namanya, mengunjungi sebuah node berarti mengunjungi atau memilih sebuah node
- Menjelajahi node (exploring a node): menjelajahi node yang berdekatan (node tetangga) dari node yang dipilih
Terdapat dua algoritma pada graph traversal yakni Depth-First Search (DFS) dan Breadth-First Search (BFS).
Pada artikel ini akan membahas salah satu algoritma dari graph traversal yakni breadth-first search.
Pengertian Breadth-First Search
Cara Kerja Algoritma Breadth-First Search
Sebelum kita mulai, Anda harus terbiasa dengan struktur data utama yang terlibat dalam algoritma Breadth first search.
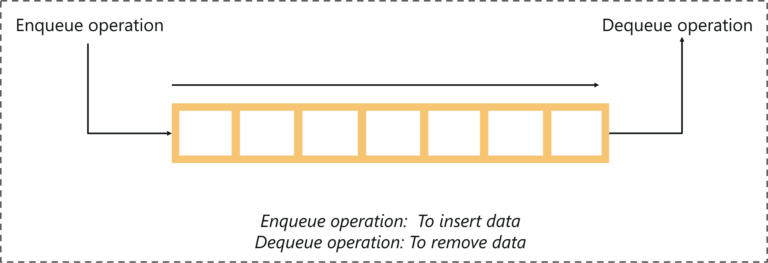
Queue adalah struktur data abstrak yang mengikuti prinsip First-In-First-Out (FIFO) yang mana data yang dimasukkan terlebih dahulu akan diakses lebih dulu. Struktur data ini terbuka di kedua ujungnya, di mana satu ujung selalu digunakan untuk memasukkan data (enqueue) dan ujung lainnya digunakan untuk menghapus data (dequeue)
 |
| Sumber: edureka.co |
Sekarang mari kita lihat langkah-langkah yang terlibat dalam melintasi grafik dengan menggunakan algoritma breadth-first search:
Langkah 1: Ambil antrian kosong.
Langkah 2: Pilih node awal (mengunjungi node) dan masukkan ke dalam antrian.
Langkah 3: Asalkan antrian tidak kosong, ekstrak node dari antrian dan masukkan node anaknya (menjelajahi node) ke dalam antrian.
Langkah 4: Cetak simpul yang diekstraksi
Pseudo code

Dalam kode di atas, langkah-langkah dijalankan sebagai berikut:
- (G, s) adalah input, di sini G adalah grafik dan s adalah simpul akar
- Antrian 'Q' dibuat dan diinisialisasi dengan node sumber 's'
- Semua simpul anak dari 's' ditandai
- Ekstrak 's' dari antrian dan kunjungi node anak
- Memproses semua simpul anak dari v
- Menyimpan w (node anak) di Q untuk mengunjungi node turunannya lebih lanjut
- Lanjutkan sampai 'Q' kosong
Contoh Proses Breadth-First Search
 |
| Sumber: edureka.co |
 |
| Sumber: edureka.co |
- Simpul atau node ‘a’ akan dianggap sebagai simpul akar dan masukkan ke dalam antrian.
- Kemudian ekstrak node 'a' dari antrian dan masukkan node anak 'a', yaitu, 'b' dan 'c'.
- Cetak simpul 'a'.
- Dapat dilihat antrian tidak kosong dan memiliki simpul 'b' dan 'c'. Karena 'b' adalah simpul pertama dalam antrian, maka diekstrak dan kemudian masukkan simpul anak dari 'b', yaitu, simpul 'd' dan 'e'.
- Ulangi langkah ini sampai antrian kosong. Perhatikan bahwa node yang sudah dikunjungi tidak boleh ditambahkan ke antrian lagi.

Kelebihan dan kekurangan
Kelebihan BFS
- Solusi pasti akan ditemukan oleh BFS apabila ada solusi.
- BFS tidak akan pernah terjebak di jalur buntu.
- Jika terdapat lebih dari satu solusi maka akan dicari solusi dengan langkah minimal.
Kekurangan BFS
- Kendala memori kerena algoritma BFS menyimpan semua node dari level saat ini untuk melanjutkan ke level berikutnya.
- Jika solusi jauh maka membutuhkan waktu yang lama.

Posting Komentar untuk "Apa itu Algoritma Breadth First Search? Pengertian dan Cara Kerjanya"
Komentar SPAM akan disensor. Harap gunakan kalimat yang tidak menjurus pada SARA dan pornografi.